感觉熟悉并行计算也是比较有竞争力的一项能力,且不说这个的应用场景还非常广泛,只要部署平台有显卡,只要有程序的地方,基本都可以考虑进行并行优化,可见它的应用还是听广泛的,并且现在支持cuda编程的语言也在增加,相信CUDA将会是以后GPU编程的主要框架。最近听说按摩店的新显卡也要支持CUDA了
GPU计算架构一览
简单的画一幅图来说明一下GPU的基本计算架构以及相关专有名词。
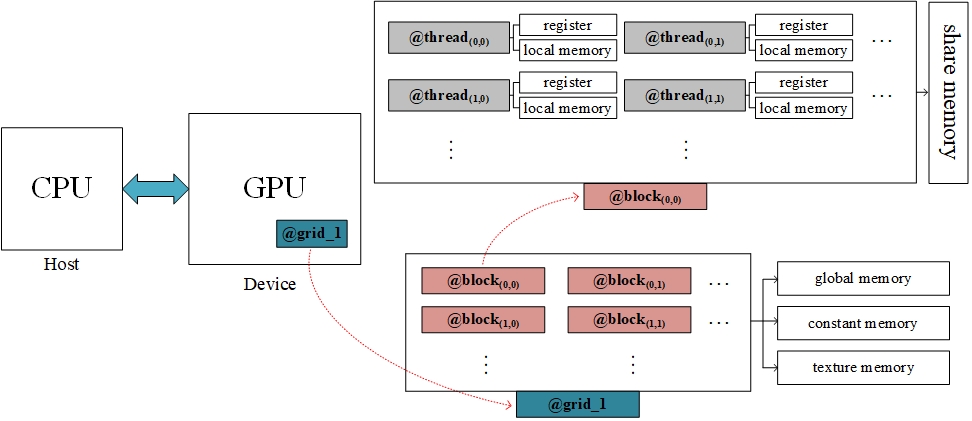
thread
在硬件上对应SP(Streaming Processor),流处理器,是运行程序的最小单位,cuda程序的并行计算具体体现在大量的SP并行运行指令。
block
在硬件上对应SM(Streaming Multi-Processor),流处理器簇,程序中定义的block也是运行在SM上的,它里面包含了一组SP,具体数量视GPU的架构和型号而定,例如:GTX 1070 一个block最多可容纳1024个thread,共有15个SM,1920个SP(也就是CUDA core),每个SM最多运行2048个SP,例如:你定义每个block有256个thread,那么在实际硬件中,每个SM上最多有8个block
grid
这个其实还是block层面的划分,当一些block正在运行同一个程序时,这堆block可以被划分为一个grid
小结:
- thread、block和grid是在软件层面的定义,在硬件的层面,实际执行的“机构”是SP和SM,这点一定要熟记于心,比如在GTX 1070上,你会发现硬件上只有1920个核心,在程序中你却可以定义核函数使用上万个thread,也就是说硬件会把你程序定义的众多thread进行分配,分多次完成,也正是这一机制,使cuda核心可以指数级的扩展
- 在实际执行的时候,调度器并不是具体去调度每个SP,而是让少量SP形成一个warp,可以有效地隐藏指令执行的延迟,一般为32个,即每32个SP组成一组,调度和执行的基本单位为warp,存储器操作的基本单位为half-warp(
即half_warp个SP执行的存储器读取或写入指令会被合并,有效的避免了内存操作产生的延迟,更新:在计算能力2.x以上的设备,存储器调度的单位也是warp)
register
这个是寄存器文件,供SP去访问,储存了SP内部活跃的寄存器
local memory
供SP使用的内部存储空间
share memory
共享存储空间,是每个SM内部的SP共用一份,不同的SM有不同的share memory
global memory、constant memory、texture memory
global memory就是全局内存,共多个SM进行访问,constant memory、texture memory都是针对global memory建立的特殊视图,constant memory用于存储一些只读的数据,texture memory用来存储插值计算需要的数据。
小结:
- GPU上的存储器均为DRAM,这就说明连续存取数据是效率最高的方式