最近准备找个实习,借此机会将CNN这块的东西回顾一下,准备花两三天时间把绝大部分的CNN网络总结一下,明白网络提出的契机,欲解决的问题等.
本文内容大部分是借鉴网上的资料.
LeNet-1998
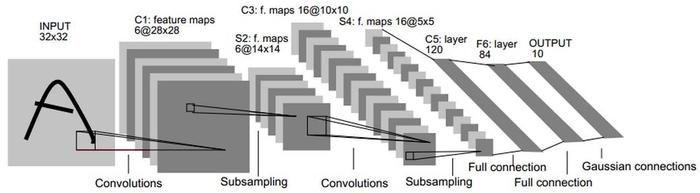
特点:
- 局部感受野(local receptive fields)
- 权值共享(weight sharing)
- 下采样(subsampling)
- 卷积+非线性激活+下采样+全连接
LeNet可以说是开了卷积神经网络的先河,它使用的结构一直沿用到现在.
AlexNet-2012
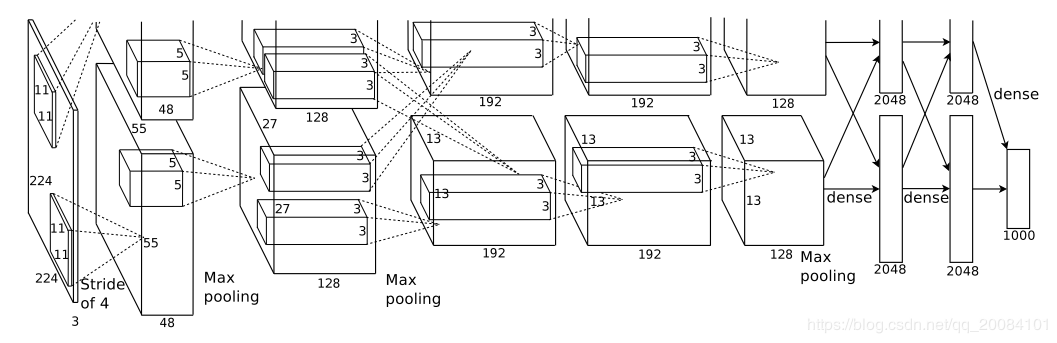
2012 年,AlexNet 横空出世,在 ILSVRC-2012 上大大超越了第二名的选手,从此深度学习进入高速发展阶段。
特点:
- 提出了ReLU激活函数,并一直沿用到现在.目前比较优秀的激活函数
- 提出了Dropout方法,这也是现在还在用的减缓过拟合的技巧.一般也用在全连接层.
- 提出了最大池化,之前的CNN普遍使用平均池化(具有模糊化效果,同时反向传播也没有最大池化有效).
- 使用了LRN,这个技巧貌似没有再用了,好像又说是这个东西其实要不要无所谓,但是其动机是好的,可以探究一下.
- 首次使用了GPU训练网络,并且还是多卡训练.
- 数据增强,不过使用的都是基本的裁剪,反转等操作
VGG-2014
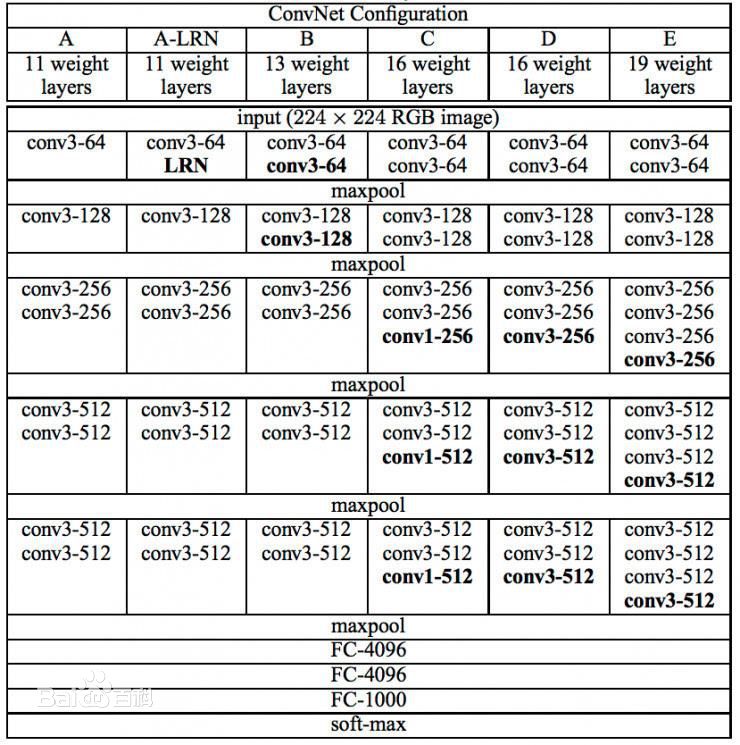
可以看出,VGG系列有很多变体,但是我们最常用的还是VGG-16,很多物体检测的backbone就是用的它.在很多迁移学习任务中,性能甚至超过了GoogLeNet,但是其参数量较大,达到了140M左右.
特点:
- 卷积核尺寸全部为3x3
- 池化的核尺寸为2x2
- 将网络进一步加深
GoogLeNet
Inception V1
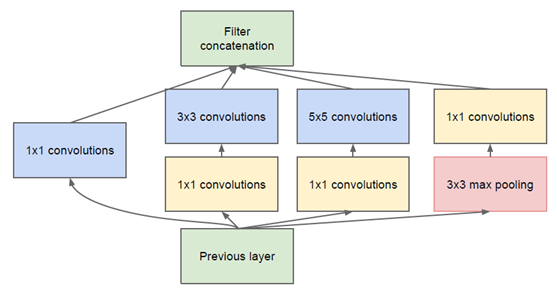
特点:
- 该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
- 在3x3,5x5卷积前面,使用1x1的卷积核降低了特征的通道数,主要是减少计算量.
- 在此之前,全连接层前面的卷积层会先flat成1x1xn的形式, 该版本的网络使用全局池化,将nxnxm的卷积特征转换为1x1xm
- 为了避免梯度消失,额外添加了两个softmax辅助训练.借用网上的一篇文章的一句话”辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。”
Inception V2
提出了BN,一直存在的神级idea.不多说.
Inception V3
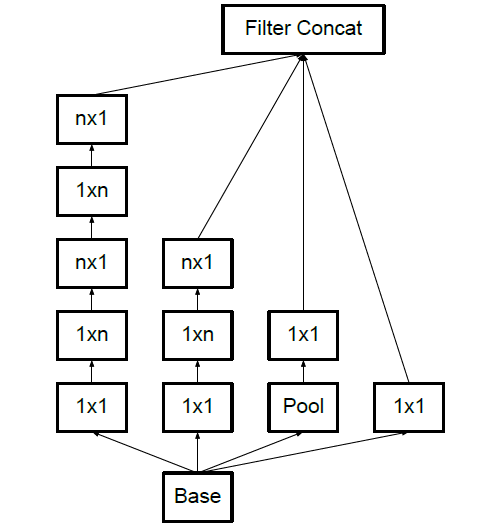
特点:
- 卷积分解(也就是我们熟知的两个3x3感受野相当于一个5x5,三个3x3相当于一个7x7,但前者的参数量都要少于后者)
- 非对称卷积,将nxn的卷积核分解为1xn和nx1串联的形式(论文指出当特征图大小为12到20时,才会有效果,其它尺寸下效果不明显,玄学)
- 使用label smoothing, 之后也有论文指出使用smooth label要好于one hot形式,基于教师-学生的one shot学习也从侧面证实了这一点.
Inception V4
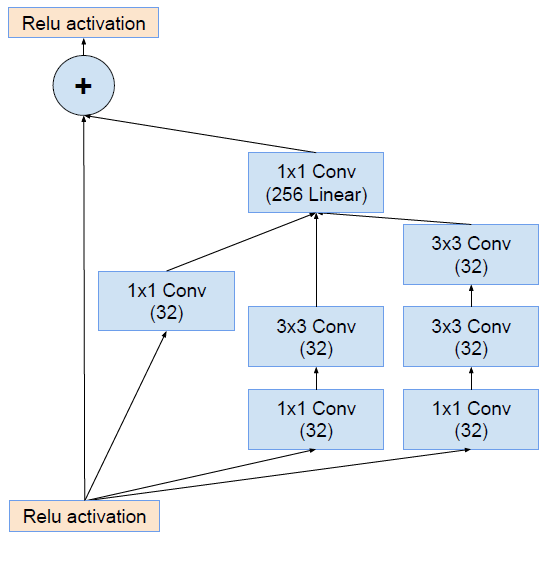
特点:
- 将Inception结构与ResNet的残差结构(见 ResNet)结合在一起.
ResNet-2015
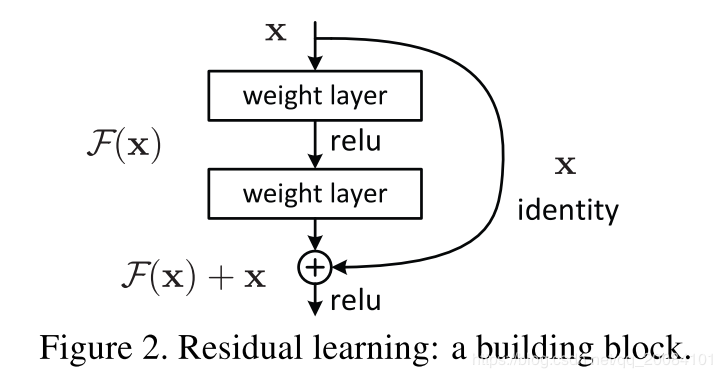
特点:
- 提出残差结构,有效地减缓了梯度消失的问题,问什么呢?因为不管网络的权重再怎么小,梯度再怎么小,至少还有个恒等映射,迫使信息进行流动,也正是这个结构使ResNet达到了150多层.
ResNet V2
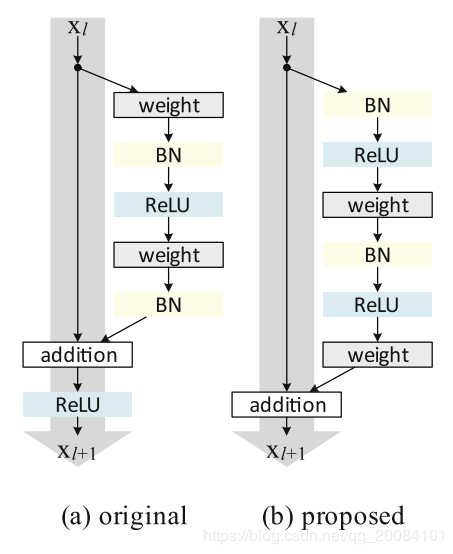
特点:
- 在 ResNet V2 中,分支中的层不像传统的 Conv-BN-ReLU 顺序,而是改成了 BN-ReLU-Conv。作者把这个称为预激活(pre-activation),其思想是将非线性激活也看成一个恒等映射(identity mapping),这样,在前向和反向阶段,信号可以直接的从一个单元传递到其他任意一个单元。这样的操作使得优化更加简单,甚至能训练深达 1001 层的 ResNet.
ResNeXt
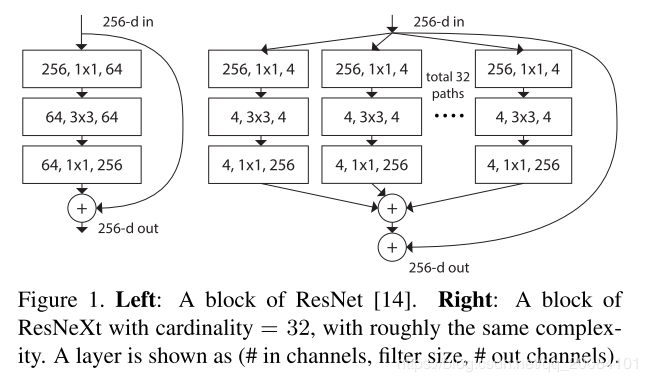
特点:
- 借鉴了inception的结构,扩展了模块的宽度,提出了 “cardinality” 概念,即一个模块并联多少个残差块(这里我有个疑问,在图中并联的残差块中,首先256通道直接降低为4通道?这样信息是不是会损失很多,还是我的理解出错了.)
WRN-2016
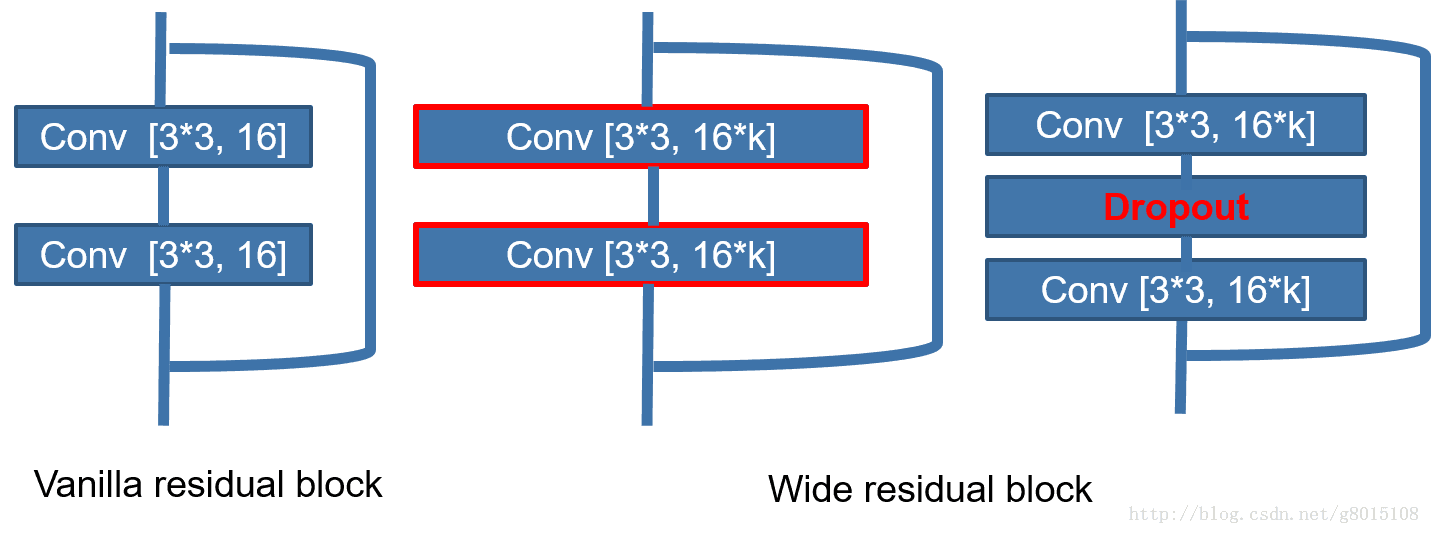
特点:
- 增加残差模块中的卷积输出通道,最后得到的结果是40层的WRN和1001层的ResNet结果相当,但是训练速度是后者的8倍,所以结论是:相同参数时,宽度大,网络好训练,并且性能不会差
DenseNet-2017
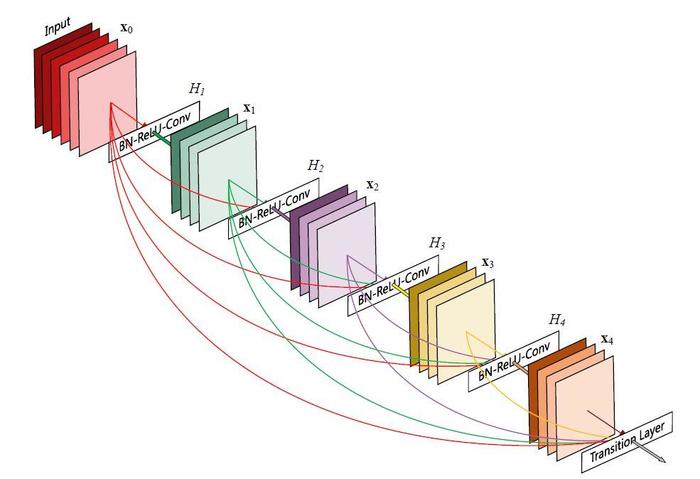
特点:
- 密集连接:缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量(可能听到密集连接,大家会想到这样不会大大加重网络的参数量吗?其实不是的,因为既然我们复用了这么多的特征层,那就没必要将新生成的特征层的通道数增大太多,其实参数量反而还能减少,因为对特征的利用率更高了,所以不用将通道扩大很多也行,这就是DenseNet最突出的优点了).
- 显存占用过大
还要注意一点,密集连接是在一个block中的,是的你没听错,DenseNet是由很多个block组成的,每个block内部才使用密集连接,block之间没有.