这篇文章主要是总结一下现阶段CNN中已有的各种激活函数,明确每种激活函数的特点,以及存在的问题。
从定义来讲,只要连续可导的函数都可以作为激活函数,但目前常见的多是分段线性和具有指数形状的非线性函数。
Sigmoid
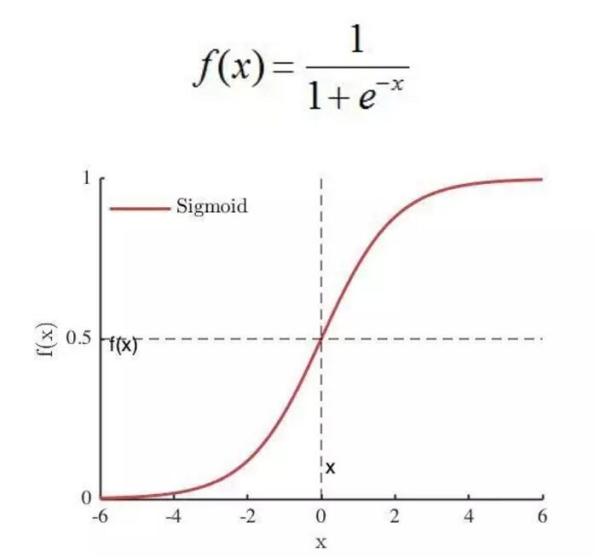
特点:
- 输出范围0-1,很符合人的主观意识,即神经元对感知的也是从不激活(0)到完全激活(1)。
- 单调连续
- 容易求导,导数为$f(x)(1-f(x))$,用自己就可以表示自己的导数。
缺陷:
- 具有软饱和性(左软饱和性指x趋近于负无穷,导数趋近于0,右饱和性指x趋近于正无穷,导数趋近于0),在输出值较大较小时,网络很难更新,因为BP算法是更具梯度来进行的,这也是所谓的梯度消失问题。
- 输出不是以0为中心,而是0.5。但是相对于前一条缺陷,影响没那么大。
Tanh
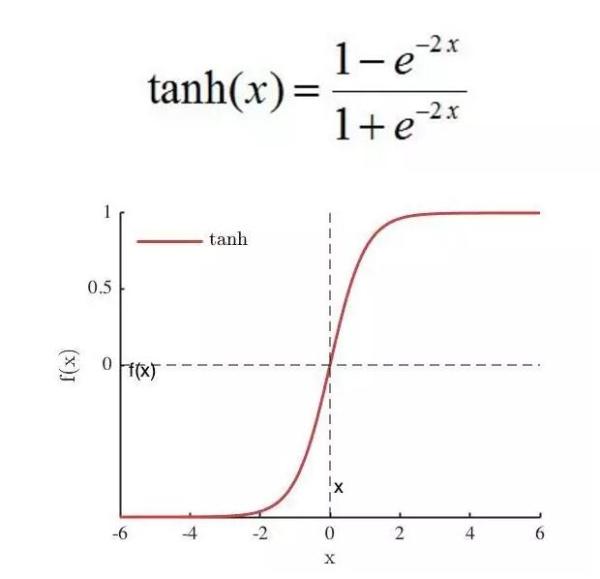
特点:
- 收敛速度比sigmoid函数快,原因是:tanh 的输出均值比 sigmoid 更接近 0,SGD会更接近natural gradient(一种二次优化技术),从而降低所需的迭代次数。
缺陷:
- 依然存在软饱和性。
ReLU
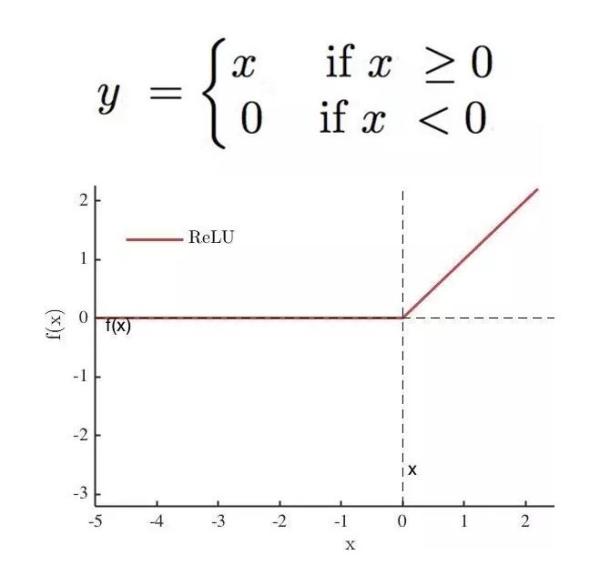
当时AlexNet提出的激活函数,非常优秀,很长一段时间是我们设计CNN网络的默认激活函数。
特点:
- 当输入为正数时,输出导数恒为1,缓解了梯度消失的问题。
- 为网络带来稀疏性,当输入值小于0,就会被稀疏掉,人的大脑稀疏性高达95%。
- 不管是正向计算,还是导数计算都非常简单。
缺点:
- 左硬饱和性,当输入小于零时,导数恒为0,会使很多神经元无法得到更新,出现“神经元死亡”。
- relu函数输出无负值。
- 均值漂移,relu函数的输出均值恒大于0(从relu函数的输出范围就能看出来)。
Leaky ReLU
公式:$f(x) = max(\alpha*x,x)$
特点:
- 为了解决relu中“神经元死亡”的问题,leaky relu给小于零的输入一个非常小的梯度。
缺点:
- 公式中的 $\alpha$ 是一个很小的值,一般取0.01,首先这就是个超参数,另外也有文献指出它的性能很不稳定,有时候比relu好,有时候差,可想而知,不太靠谱。
PReLU
公式和Leaky ReLU一样,只不过它的 $\alpha$ 参数是可学习的。
特点:
- 收敛速度比relu快。
- 输出均值更接近0。
缺点:
- 目前还不清楚,只能说表现还不稳定,不够“通用”,其作者何凯明在他的ResNet也没使用,而是使用的ReLU。
RReLU
和PReLU类似,只不过它这里的 $\alpha$ 参数是一个高斯分布上的随机值,在测试时固定。
ELU
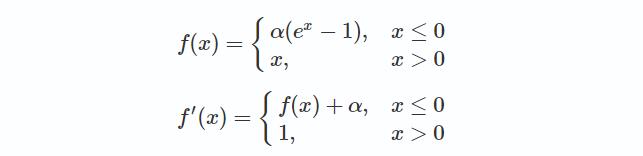
特点:
- 较高的噪声鲁棒性。
- 输出均值在0附近。
缺点:
- 存在指数运算,运算量较大。
SELU
牛逼的地方是提出该方法的论文后面有长达93页的论证。
公式:$f(x)=\lambda*ELU(x)$
特点(摘自知乎回答):
- 新增的参数 $\lambda$ 大于1,所以在正半轴,函数的导数是大于1的。
- 激活函数有一个不动点,网络深了以后每一层的输出都会向正态分布靠拢,美其名曰自归一化。
缺点(摘自知乎回答):
- selu的证明部分前提是权重服从正态分布,但是这个假设在实际中并不能一定成立,比如钟形分布?(不太懂)
- 众多实验发现效果并不比relu好。
CReLU
公式:$CReLU(x)=[ReLU(x),ReLU(-x)]$
作者发现在网络的浅层卷积核更倾向于捕捉正负相位的信息,而ReLU会将负相位的信息归0,所以才有了CReLU操作。
特点:
- 输出通道数翻倍,相当于利用对称的关系,将负相位的信息人为恢复出来。
缺点:
- 到底在哪些层使用,太依赖调试了。
Maxout
公式:$max(w_1^Tx+b_1,w_2^Tx+b_2,…,w_n^Tx+b_n)$
它是ReLU的推广,其发生饱和是一个零测集事件(不懂什么意思…),具有一个参数k。
特点:
- maxout可以拟合任意的凸函数。
- 具备relu的所有优点。
- 不会出现神经元死亡。
缺点:
- (不错的解释)参数量巨大(以k倍增加),因为之前我们每个神经元只需要一组权重和偏置,现在不是了,我们添加了冗余的k组权重和偏置,让输入均经过这些权重和偏置计算,只保留激活值最大的输出。
Swish
公式:$f(x) = x*sigmoid(\beta*x)$,其中 $\beta$ 参数可以是常数也可以是训练的。
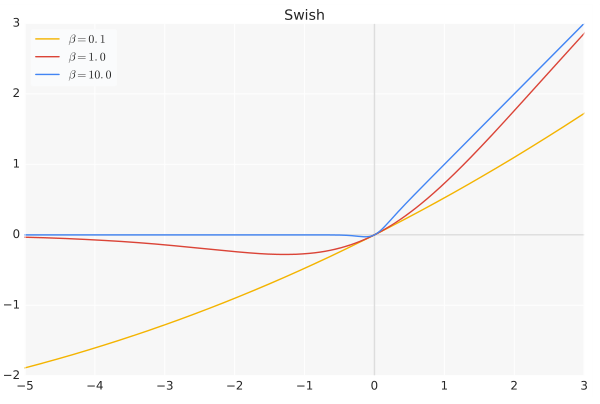
特点:
- 无上界有下界、平滑、非单调。
- Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
- 论文给出的实验,各种数据集上,各种网络,都比relu性能好(并且在深层网络上优势更大)。
缺点:
- 只有实验证明,没有理论支持。
- 在浅层网络上,性能与relu差别不大。
参考
- https://www.cnblogs.com/makefile/p/activation-function.html
- https://www.cnblogs.com/ranjiewen/p/5918457.html?utm_source=itdadao&utm_medium=referral